Share this
by ModuleQ on Oct 28, 2024 8:05:12 AM
From Words to Vectors: Understanding AI's Mathematical Language
What are Embeddings?
Embeddings are the computed representations of textual information as mathematical objects. We'll focus on text for the purpose of this post! Those objects take the form of vectors, which we'll unpack a bit later. Embeddings allow machine learning and AI models to compare and ultimately understand relationships and patterns within data.
As we highlighted in our posts about Large Language Models (LLMs), these models take vast swaths of text and use a deep learning approach called transformers to build an understanding of the meaning of that text. Part of that process is transforming text into numerical values, after which similarity can be better deduced.
Focusing on understanding relationships in language has long been a challenge for researchers and linguists alike. Language is fluid which makes its decomposition through rules particularly difficult. Comparing a hornet's nest to a lion's den and a firestorm is challenging to parse out from a pure meaning standpoint, especially when building one's understanding through the words in the phrase. But the ability of transformers to provide mathematical approximations of words or phrases to other terms within sentences unlocks their ability to deduce the complex meaning of disconnected phrases in relationship to other words. The building blocks of that process are embeddings.
The following walkthrough by Google does a good job of unpacking embeddings step by step.
How is Similarity Deduced Across Embeddings?
To understand this, we suggest refreshing one's understanding of vectors, a core foundation of linear algebra. Linear algebra powers much of the mathematical and computer science backbone of the embeddings process, enabling natural language processing.
The key question is how can you take vectors and analyze their similarity? This is integral in our example of unpacking the similarity in meaning between hornet's nest, lion's den, and firestorm.
There are various statistical measures of similarity used in data analysis. They can be as simple as understanding the distance between two points on a line, to as complex as comparing the similarity of a matrix (another linear algebra concept). For the purpose of analyzing embeddings, ModuleQ leverages cosine similarity.
To simplify, cosine similarity allows a vectoral embedding representing textual information to be assigned a distance to other vectors, as the illustration below would show across single words/phrases. Note how it deduces the similarity between truck and towing, in contrast to truck and convertible:
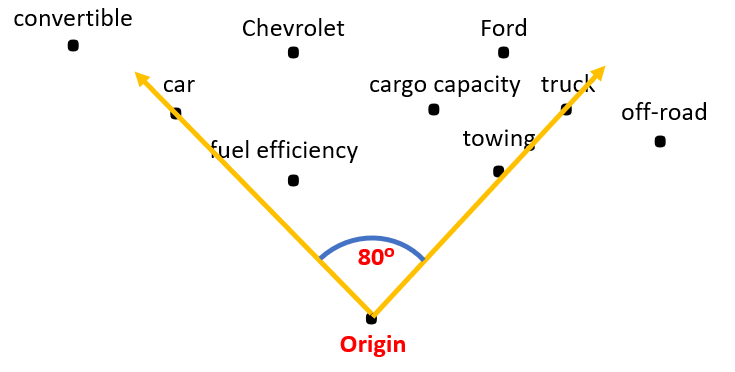
Why Does ModuleQ Analyze Embedding Similarity?
We are not a Generative AI company per se. However, we leverage cutting edge tools under the umbrella of Gen AI for specific use cases. Our goal is often to improve information relevance, and embeddings can be a powerful tool in doing so.
Just as understanding the distance between particular words is foundational to how an LLM probabilistically deduces the next word in a sentence, we can leverage the same capabilities for routing relevant and personalized information to a user based upon who they are, what they find relevant, and what they've found useful in the past. For example, if a user found a particular bit of research helpful, we can vectorize descriptive aspects of that research, comparing it to other research for similarity and ultimate delivery.
So, we analyze embeddings for the purposes of personalizing recommendations of news, company specific data, internal account information and the entire spectrum of alerts that improve our users' productivity. When used properly, they are a powerful tool in routing the right information to the right person at the right time.
Embeddings as defined by:
Cloudflare: Embeddings are representations of values or objects like text, images, and audio that are designed to be consumed by machine learning models and semantic search algorithms. They translate objects like these into a mathematical form according to the factors or traits each one may or may not have, and the categories they belong to.
AWS: Embeddings enable deep-learning models to understand real-world data domains more effectively. They simplify how real-world data is represented while retaining the semantic and syntactic relationships. This allows machine learning algorithms to extract and process complex data types and enable innovative AI applications. The following sections describe some important factors.
Salesforce: Digital transformation is the process of using digital technologies to create new — or modify existing — business processes, culture, and customer experiences to meet changing business and market requirements. This reimagining of business in the digital age is digital transformation.